
Одним из важнейших факторов влияния на позиции сайта в выдаче является его контентное наполнение. Естественно, что как SEO-оптимизаторы, так и сами владельцы сайтов, стремятся к тому, чтоб наполнить веб-ресурс уникальным, качественным, интересным контентом. Но существуют и такие недоброжелатели, которые просто «воруют» информацию из других ресурсов и выдают ее как свою. Несправедливость заключается в том, что после индексации данные страницы могут подняться в выдаче даже выше, нежели страницы с оригинальным текстом. Но существует и ряд манипуляций, способных защитить контент от копирования со стороны конкурентов и профессиональных монетизаторов. В данной статье рассмотрим несколько самых популярных шагов.
Самым известным инструментом для копирования контента является система парсинга. Это автоматизированная система, поведение которой существенным образом отличается от поведения реальных пользователей. Для защиты необходимо обнаружить среди посетителей автоматический парсер и заблокировать его на уровне сервера.
Тут предлагается два способа:
Проверка на JavaScript. Системы парсинга очень просто распознать при помощи проверки на использование JavaScript. Если же скрипт не выполняется, то высока вероятность того, что Ваш ресурс посещает робот. В том случае, если Вы рассчитываете, что все-таки существует вероятность того, что сайт будет посещать юзер с полностью отключенным JavaScript, то логичным становится подключение к сайту инструмента прохождения капчи.
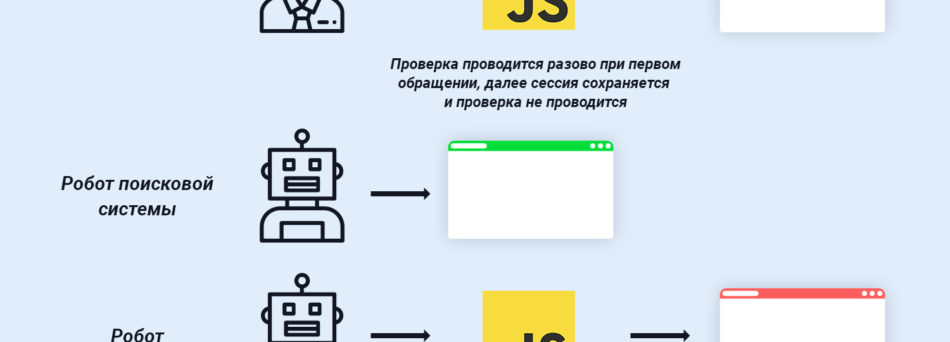
Также стоит принять во внимание и краулеров поисковых систем, и исключить их из блокировки. Списки краулеров представлены на официальных сайтах поисковых систем.
Проверка на действие. Современные разработчики систем парсинга научились создавать инструменты, имитирующие включенный JavaScript. В таких случаях, вышеописанные способы не смогут идентифицировать робота. Для того, чтоб заблокировать такие системы парсинга, стоит определить главные цели его работы. А это – сканирование и копирование ценного контента. Путем анализа логов сервера происходит сбор IP-адресов парсеров. Следующий шаг – блокировка доступа к сайту. Для этого используется файл директив сервера .htaccess.
Помимо описанных выше способов можно еще воспользоваться алгоритмами, анализирующими скорость клика, провести «тест на клик», анализ движения курсора.
Большинство современных сайтов имеют установленную генерацию карты сайта sitemap.xml, куда вносится список ссылок на страницы, подлежащие индексации. Основная задача карты сайта – оповещение ПС, о появлении новых страниц.
Но случаются ситуации, что автоматизированные системы парсинга узнают, о появлении новой страницы раньше, нежели роботы поисковых систем. Это позволяет скопировать новый контент и опубликовать его на сайте с копиями. Далее проводится ускоренная индексация страниц (например при помощи инструмента GetSocial) и поисковые роботы определяют копию, как оригинал.
К счастью, поисковым системам давно известны данные схемы работы парсеров и они предлагаются воспользоваться социальными инструментами – Google Search Console Sitemaps и Yandex Webmaster.
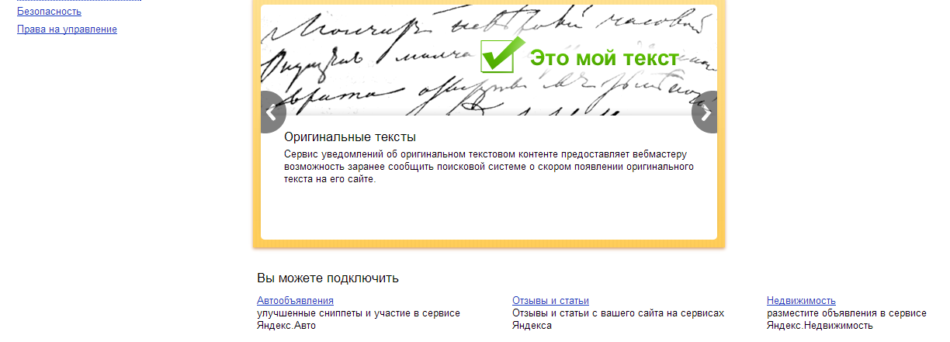
Поисковая система Яндекс предлагает воспользоваться специальным инструментом для уведомления о появлении нового оригинального текста на сайте. Он так и называется «Оригинальные тексты». Перед тем, как загрузить текст на сам сайт, загружаем его в систему, для того, чтоб при ранжировании результатов учитывался именно источник оригинального контента.
К сожалению, ПС Google не предлагает подобных инструментов, но зато предусмотрена возможность удаления страниц конкурентов, на которых размещен скопированный текст. Для этого в сфере Интернет-маркетинга существует такое понятие, как DMCA (THE DIGITAL MILLENNIUM COPYRIGHT ACT Summary). Закон, принятый в США в области авторского права для защиты контента на цифровых носителях, в том числе и в Интернете. Согласно закону каждый пользователь имеет полное право обратиться в Google и подать запрос на удаление страницы с неоригинальным контентом.
Проверить текст на уже существующие копии можно, воспользовавшись специальным бесплатным сервисом MegaIndex. Также предусмотрена возможность, позволяющая отслеживать появление новых копий контента по мониторингу воспоминаний. Но для этого потребуется указывать, например, название компании или бренда в каждой статье, которая публикуется на сайте. В дальнейшем для отслеживания репутации сайта в Интернете можно отслеживать упоминания о компании, таким образом, идентифицируя появление новых копий Вашего контента. Тут задействуется сервис MegaIndex Search Engine Reputation Management.

Уникальный, оригинальный контент на сайте поможет не просто улучшить ранжирование ресурса и повысить его позиции в выдаче. Это также отличный инструмент привлечения целевой аудитории, которая в дальнейшем превращается в потенциального клиента. Одним из важнейших этапов продвижения от компании «PROject SEO» является наполнение ресурса уникальным контентом и комплекс мер по защите от копирования конкурентами.

Главный редактор.
🔮 Google AI Mode, 🐦 Grok, 🔍 Perplexity, 💬 ChatGPT, 🤖 Claude.ai.
 Как ChatGPT и AI Overview меняют воронку продаж: что теряет бизнес и как адаптировать сайт
Как ChatGPT и AI Overview меняют воронку продаж: что теряет бизнес и как адаптировать сайт  Google официально переводит поиск в AI Mode: что это значит для SEO и бизнеса
Google официально переводит поиск в AI Mode: что это значит для SEO и бизнеса  Сколько стоит SEO продвижение сайта в Украине?
Сколько стоит SEO продвижение сайта в Украине?  Как оптимизировать товары под AI-рекомендации: полный гайд для e-commerce
Как оптимизировать товары под AI-рекомендации: полный гайд для e-commerce  Идеи для бизнеса 2026
Идеи для бизнеса 2026  SEO-оптимизация сайта под требования AI
SEO-оптимизация сайта под требования AI  9 примеров контента, которым захотят поделиться
9 примеров контента, которым захотят поделиться  Как Хорошоп.Export помогает украинским предпринимателям успешно реализовывать свои товары за границей
Как Хорошоп.Export помогает украинским предпринимателям успешно реализовывать свои товары за границей 
 Как ChatGPT и AI Overview меняют воронку продаж: что теряет бизнес и как адаптировать сайт
Как ChatGPT и AI Overview меняют воронку продаж: что теряет бизнес и как адаптировать сайт Google официально переводит поиск в AI Mode: что это значит для SEO и бизнеса
Google официально переводит поиск в AI Mode: что это значит для SEO и бизнеса Сколько стоит SEO продвижение сайта в Украине?
Сколько стоит SEO продвижение сайта в Украине? Как оптимизировать товары под AI-рекомендации: полный гайд для e-commerce
Как оптимизировать товары под AI-рекомендации: полный гайд для e-commerce Идеи для бизнеса 2026
Идеи для бизнеса 2026
 Как узнать CMS сайта?
Как узнать CMS сайта?  10 популярных CMS для интернет-магазинов
10 популярных CMS для интернет-магазинов  301 редирект на сайте: правильная настройка htaccess
301 редирект на сайте: правильная настройка htaccess  Как узнать и проверить посещаемость сайта
Как узнать и проверить посещаемость сайта  Проверка текста на уникальность: обзор лучших сервисов
Проверка текста на уникальность: обзор лучших сервисов  Лучшие платежные системы для сайта и Интернет-магазина
Лучшие платежные системы для сайта и Интернет-магазина  Как проверить сайт на вирусы и вредоносный код?
Как проверить сайт на вирусы и вредоносный код?  Как добавить сайт в поисковые системы Google
Как добавить сайт в поисковые системы Google  Советы как назвать интернет-магазин
Советы как назвать интернет-магазин  Как заработать в интернете реальные деньги без вложений? Идеи для бизнеса 2026
Как заработать в интернете реальные деньги без вложений? Идеи для бизнеса 2026  Что такое Лендинг Пейдж (Landing Page)
Что такое Лендинг Пейдж (Landing Page)  SWOT анализ онлайн-бизнеса
SWOT анализ онлайн-бизнеса 








Комментарии к статье